Unbiased estimation of standard deviation
The question of unbiased estimation of a standard deviation arises in statistics mainly as question in statistical theory. Except in some important situations, outlined later, the task has little relevance to applications of statistics since its need is avoided by standard procedures, such as the use of significance tests and confidence intervals, or by using Bayesian analysis.
However, for statistical theory, it provides an exemplar problem in the context of estimation theory which is both simple to state and for which results cannot be obtained in closed form. It also provides an example where imposing the requirement for unbiased estimation might be seen as just adding inconvenience, with no real benefit.
Contents |
Background
In statistics, the standard deviation is often estimated from a random sample drawn from the population. The most common measure used is the sample standard deviation, which is defined by
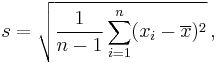
where 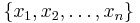 is the sample (formally, realizations from a random variable X) and
is the sample (formally, realizations from a random variable X) and 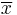 is the sample mean.
is the sample mean.
One way of seeing that this is a biased estimator of the standard deviation of the population is to start from the result that s2 is an unbiased estimator for the variance σ2 of the underlying population if that variance exists and the sample values are drawn independently with replacement. The square root is a nonlinear function, and only linear functions commute with taking the expectation. Since the square root is a concave function, it follows from Jensen's inequality that the square root of the sample variance is an underestimate.
The use of n − 1 instead of n in the formula for the sample variance is known as Bessel's correction, which corrects the bias in the estimation of the sample variance, and some, but not all of the bias in the estimation of the sample standard deviation.
It is not possible to find an estimate of the standard deviation which is unbiased for all population distributions, as the bias depends on the particular distribution. Much of the following relates to estimation assuming a normal distribution.
Bias correction
Results for the normal distribution
When the random variable is normally distributed, a minor correction exists to eliminate the bias. To derive the correction, note that for normally distributed X, Cochran's theorem implies that the square of 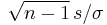 has a chi distribution with n − 1 degrees of freedom. Consequently,
has a chi distribution with n − 1 degrees of freedom. Consequently,
![\operatorname{E}[s] = c_4(n)\sigma \,](/2012-wikipedia_en_all_nopic_01_2012/I/348ca38d05e808ff1c181298434c3e02.png)
where c4(n) depends on the sample size n as follows:
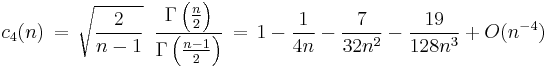
and Γ(·) is the gamma function. An unbiased estimator of σ can be obtained by dividing s by c4(n). As n grows large it approaches 1, and even for smaller values the correction is minor. The figure shows a plot of c4(n) versus sample size. The table below gives numerical values of c4 and algebraic expressions for a some values of n; more complete tables may be found in most textbooks on statistical quality control.
| Sample size | Expression of c4 | Numerical value |
|---|---|---|
| 2 | 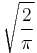 |
0.7978845608 |
| 3 | 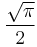 |
0.8862269255 |
| 4 | 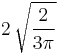 |
0.9213177319 |
| 5 | 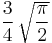 |
0.9399856030 |
| 6 | 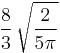 |
0.9515328619 |
| 7 | 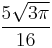 |
0.9593687891 |
| 8 | 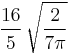 |
0.9650304561 |
| 9 | 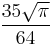 |
0.9693106998 |
| 10 | 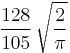 |
0.9726592741 |
| 100 | 0.9974779761 | |
| 1000 | 0.9997497811 | |
| 10000 | 0.9999749978 | |
| n = 2k | 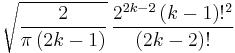 |
|
| n = 2k+1 | 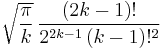 |
It is important to keep in mind this correction only produces an unbiased estimator for normally and independently distributed X. When this condition is satisfied, another result about s involving c4(n) is that the standard error of s is[1][2] 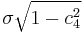 , while the standard error of the unbiased estimator is
, while the standard error of the unbiased estimator is 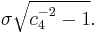
Rule of thumb
If calculation of the function c4(n) appears too difficult, there is a simple rule-of-thumb to take the estimator
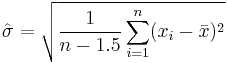
The formula differs from the familiar expression for s2 only be having n − 1.5 instead of n − 1 in the denominator. This expression is unbiased only approximately, in fact
![\operatorname{E}[\hat\sigma] = \sigma\cdot\Big( 1 %2B \frac{1}{16n^2} %2B \frac{3}{16n^3} %2B O(n^{-4}) \Big).](/2012-wikipedia_en_all_nopic_01_2012/I/9a61bfd2a557a591c807925522b1c07d.png)
However the bias is relatively small: say, for n = 3 it is equal to 1.3%, and for n = 9 the bias is already less than 0.1%.
Other distributions
In cases where statistically independent data are modelled by a parametric family of distributions other than the normal distribution, the population standard deviation will, if it exists, be a function of the parameters of the model. One general approach to estimation would be maximum likelihood. Alternatively, it may be possible to use the Rao–Blackwell theorem as a route to finding a good estimate of the standard deviation. In neither case would the estimates obtained usually be unbiased. Notionally, theoretical adjustments might be obtainable to lead to unbiased estimates but, unlike those for the normal distribution, these would typically depend on the estimated parameters.
If the requirement is simply to reduce the bias of an estimated standard deviation, rather than to eliminate it entirely, then two practical approaches are available, both within the context of resampling. These are jackknifing and bootstrapping. Both can be applied either to parametrically-based estimates of the standard deviation or to the sample standard deviation.
For non-normal distributions an approximate (up to O(n−1) terms) formula for the unbiased estimator of the standard deviation is
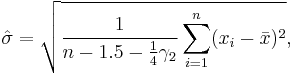
where γ2 denotes the population excess kurtosis. The excess kurtosis may be either known beforehand for certain distributions, or estimated from the data.
Effect of autocorrelation (serial correlation)
The material above, to stress the point again, applies only to independent data. However, real-world data often does not meet this requirement; it is autocorrelated (also known as serial correlation). As one example, the successive readings of a measurement instrument that incorporates some form of “smoothing” (more correctly, “filtering”) process will be autocorrelated, since the current reading is calculated from some combination of the prior readings.
Estimates of the variance, and standard deviation, of autocorrelated data will be biased. The expected value of the sample variance is[3]
![{\rm E}\left[ {s^2 } \right]\,\, = \,\,\sigma ^2 \,\left[ {1\,\,\, - \,\,\,{2 \over {n - \,\,1}}\,\,\sum\limits_{k\, = \,1}^{n\, - 1} {\,\left( {1\,\, - \,\,{k \over n}} \right)\rho _k } } \right]](/2012-wikipedia_en_all_nopic_01_2012/I/50265b03b105b2d62aad18a16b621039.png)
where n is the sample size (number of measurements) and 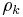 is the autocorrelation function (ACF) of the data. If the ACF consists of positive values then the estimate of the variance (and its square root, the standard deviation) will be biased low. That is, the actual variability of the data will be greater than that indicated by an uncorrected variance or standard deviation calculation. It is essential to recognize that, if this expression is to be used to correct for the bias, by dividing the estimate
is the autocorrelation function (ACF) of the data. If the ACF consists of positive values then the estimate of the variance (and its square root, the standard deviation) will be biased low. That is, the actual variability of the data will be greater than that indicated by an uncorrected variance or standard deviation calculation. It is essential to recognize that, if this expression is to be used to correct for the bias, by dividing the estimate 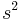 by the quantity in brackets above, then the ACF must be known analytically, not via estimation from the data. This is because the estimated ACF will itself be biased.[4]
by the quantity in brackets above, then the ACF must be known analytically, not via estimation from the data. This is because the estimated ACF will itself be biased.[4]
Example of bias in standard deviation
To illustrate the magnitude of the bias in the standard deviation, consider a dataset that consists of sequential readings from an instrument that uses a specific digital filter whose ACF is known to be given by
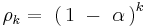
where α is the parameter of the filter, and it takes values from zero to unity. Thus the ACF is positive and geometrically decreasing. The figure shows the ratio of the estimated standard deviation to its known value (which can be calculated analytically for this digital filter), for several settings of α as a function of sample size n. Changing α alters the variance reduction ratio of the filter, which is known to be
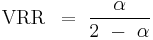
so that smaller values of α result in more variance reduction, or “smoothing.” The bias is indicated by values on the vertical axis different from unity; that is, if there were no bias, the ratio of the estimated to known standard deviation would be unity. Clearly, for modest sample sizes there can be significant bias (a factor of two, or more).
Variance of the mean
It is often of interest to estimate the variance or standard deviation of an estimated mean rather than the variance of a population. When the data are autocorrelated, this has a direct effect on the theoretical variance of the sample mean, which is[5]
![{\rm Var}\left[ \bar x \right]\,\,\, = \,\,{{\sigma ^2 } \over n}\,\left[ {1\,\,\, %2B \,\,\,2\,\sum\limits_{k\, = \,1}^{n - 1} {\left( {1\,\, - \,\,{k \over n}} \right)\rho _k } } \right] .](/2012-wikipedia_en_all_nopic_01_2012/I/7605fd329311544c8859a9ab49973b4a.png)
The variance of the sample mean can then be estimated by substituting an estimate of σ2. One such estimate can be obtained from the equation for E[s2] given above. First define the following constants, assuming, again, a known ACF:
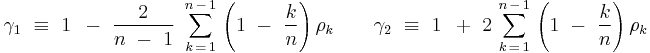
so that
![{\rm E}\left[ {s^2 } \right]\,\, = \,\,\sigma ^2 \,\gamma _1 \,\,\,\,\,\, \Rightarrow \,\,\,\,\,\,{\rm E}\left[ {{{s^2 } \over {\gamma _1 }}} \right]\,\,\, = \,\,\,\sigma ^2](/2012-wikipedia_en_all_nopic_01_2012/I/3a3777c78039e36810434594aa1ce131.png)
This says that the expected value of the quantity obtained by dividing the observed sample variance by the correction factor 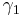 gives an unbiased estimate of the variance. Similarly, re-writing the expression above for the variance of the mean,
gives an unbiased estimate of the variance. Similarly, re-writing the expression above for the variance of the mean,
![{\rm Var}\left[ {\bar x} \right]\,\,\, = \,\,\,{{\sigma ^2 } \over n}\,\,\gamma _2](/2012-wikipedia_en_all_nopic_01_2012/I/e0cb0b35d2d1ac4af67a734a2fe614af.png)
and substituting the estimate for 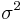 gives[6]
gives[6]
![{\rm Var}\left[ {\bar x} \right]\,\,\, = \,\,\,{\rm E}\left[ {{{s^2 } \over {\gamma _1 }}\left( {{{\gamma _2 } \over n}} \right)} \right]\,\,\,\, = \,\,\,{\rm E}\left[ {{{s^2 } \over n}\left\{ {{{n\,\, - \,\,1} \over {{n \over {\gamma _2 }} - \,\,1}}} \right\}} \right]](/2012-wikipedia_en_all_nopic_01_2012/I/4b33053b593cc907587da749a3a9ce29.png)
which is an unbiased estimator of the variance of the mean in terms of the observed sample variance and known quantities. Note that, if the autocorrelations are identically zero, this expression reduces to the well-known result for the variance of the mean for independent data. The effect of the expectation operator in these expressions is that the equality holds in the mean (i.e., on average).
Estimating the standard deviation of the population
Having the expressions above involving the variance of the population, and of an estimate of the mean of that population, it would seem logical to simply take the square root of these expressions to obtain unbiased estimates of the respective standard deviations. However it is the case that, since expectations are integrals,
![{\rm E}[s]\,\,\, \ne \,\,\sqrt {\,{\rm E}\left[ {s^2 } \right]} \,\,\, \ne \,\,\,\sigma \,\sqrt {\,\gamma _1 }](/2012-wikipedia_en_all_nopic_01_2012/I/375f6b56253d7d0032b67d6c30f49653.png)
Instead, assume a function θ exists such that an unbiased estimator of the standard deviation can be written
![{\rm E}\left[ s \right]\,\,\, = \,\,\,\sigma \,\,\theta \sqrt {\,\gamma _1 } \,\,\,\,\,\,\,\, \Rightarrow \,\,\,\,\,\,\,\hat \sigma \,\, = \,\,{s \over {\theta \,\sqrt {\,\gamma _1 } }}](/2012-wikipedia_en_all_nopic_01_2012/I/19092ef6a4de410a02127edcfbc53cdd.png)
and θ depends on the sample size n and the ACF. In the case of NID (normally and independently distributed) data, the radicand is unity and θ is just the c4 function given in the first section above. As with c4, θ approaches unity as the sample size increases (as does γ1).
It can be demonstrated via simulation modeling that ignoring θ (that is, taking it to be unity) and using
![{\rm E}[s]\,\, \approx \,\,\sigma \,\sqrt {\,\gamma _1 } \,\,\,\,\,\,\,\,\,\,\Rightarrow \,\,\,\,\,\,\,\,\,\hat \sigma \,\,\, \approx \,\,\,{s \over {\sqrt {\,\gamma _1 } }}](/2012-wikipedia_en_all_nopic_01_2012/I/b7553de1858d091c0a94cf7e75ace123.png)
removes all but a few percent of the bias caused by autocorrelation, making this a reduced-bias estimator, rather than an unbiased estimator. In practical measurement situations, this reduction in bias can be significant, and useful, even if some relatively small bias remains. The figure above, showing an example of the bias in the standard deviation vs. sample size, is based on this approximation; the actual bias would be somewhat larger than indicated in those graphs since the transformation bias θ is not included there.
Estimating the standard deviation of the mean
The unbiased variance of the mean in terms of the population variance and the ACF is given by
![{\rm Var}\left[ {\bar x} \right]\,\,\, = \,\,\,{{\sigma ^2 } \over n}\,\,\gamma _2 \,](/2012-wikipedia_en_all_nopic_01_2012/I/e8ed0927ddf8be428c92f481284c7ceb.png)
and since there are no expected values here, in this case the square root can be taken, so that
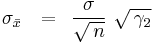
Using the unbiased estimate expression above for σ, an estimate of the standard deviation of the mean will then be
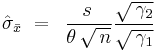
If the data are NID, so that the ACF vanishes, this reduces to
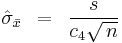
In the presence of a nonzero ACF, ignoring the function θ as before leads to the reduced-bias estimator
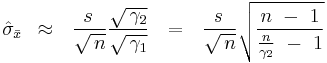
which again can be demonstrated to remove a useful majority of the bias.
See also
References
- Douglas C. Montgomery and George C. Runger, Applied Statistics and Probability for Engineers, 3rd edition, Wiley and sons, 2003. (see Sections 7–2.2 and 16–5)
- ^ Duncan, A. J., Quality Control and Industrial Statistics 4th Ed., Irwin (1974) ISBN 0-256-01558-9, p.139
- ^ * N.L. Johnson, S. Kotz, and N. Balakrishnan, Continuous Univariate Distributions, Volume 1, 2nd edition, Wiley and sons, 1994. ISBN 0-471-58495-9. Chapter 13, Section 8.2
- ^ Law and Kelton, Simulation Modeling and Analysis, 2nd Ed. McGraw-Hill (1991), p.284, ISBN 0-07-036698-5. This expression can be derived from its original source in Anderson, The Statistical Analysis of Time Series, Wiley (1971), ISBN 0-471-04745-7, p.448, Equation 51.
- ^ Law and Kelton, p.286. This bias is quantified in Anderson, p.448, Equations 52–54.
- ^ Law and Kelton, p.285. This equation can be derived from Theorem 8.2.3 of Anderson. It also appears in Box, Jenkins, Reinsel, Time Series Analysis: Forecasting and Control, 4th Ed. Wiley (2008), ISBN 978-0-470-27284-8, p.31.
- ^ Law and Kelton, p.285
External links
- A Java interactive graphic showing the Helmert PDF from which the bias correction factors are derived.
- Monte-Carlo simulation demo for unbiased estimation of standard deviation.
- http://www.itl.nist.gov/div898/handbook/pmc/section3/pmc32.htm What are Variables Control Charts?
This article incorporates public domain material from websites or documents of the National Institute of Standards and Technology.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||